Data Retriever
Il Data Retriever è un servizio architetturale che automatizza, centralizza, standardizza la gestione delle risorse informative da pubblicare o aggiornare nei diversi Data Space attraverso i connettori IDS.
Se il Participant Template agisce all’interno del connettore, il Data Retriever lavora a monte, agisce come un orchestratore tra:
- Sistemi interni / sorgenti dati.
- Cataloghi informativi.
- Connettori IDS verso uno o più Data Space.
Questo servizio:
- recupera automaticamente dataset e metadati da piattaforme interne; li arricchisce e li prepara secondo le regole del Data Space; li pubblica tramite i connettori registrati;
- mantiene aggiornati i dataset nel tempo;
- gestisce la partecipazione dell’organizzazione a più Data Space contemporaneamente.
Il Data Retriever evita duplicazioni, riduce l’errore umano e garantisce che ciò che viene condiviso sia sempre aggiornato. Inoltre, grazie a standard di sicurezza come OAuth2 e l’uso di sistemi di gestione identità (come Keycloak), assicura che ogni accesso sia autorizzato e conforme alle policy stabilite dal proprietario dei dati.
Il Data Retriever è concepito, quindi, come servizio a supporto della gestione operativa dei dati di tracciabilità lungo le diverse fasi della filiera. Come illustrato nel seguente schema architetturale:
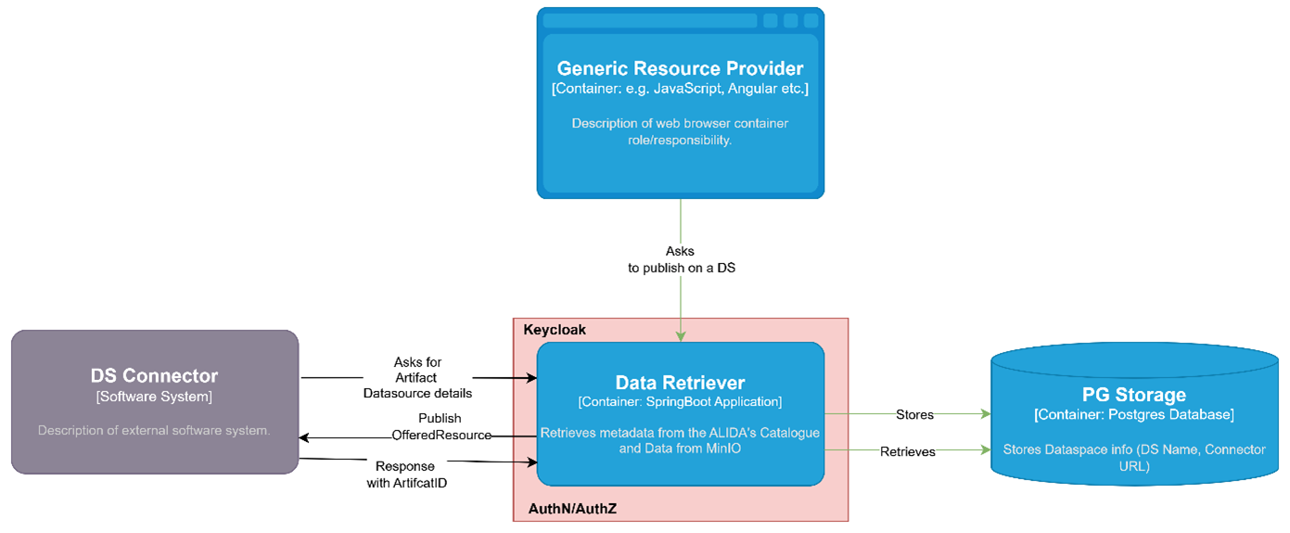
il Data Retriever opera come componente intermedio tra i sistemi che producono o forniscono dati, i cataloghi informativi e i Data Space, svolgendo una funzione di orchestrazione dei processi di pubblicazione e gestione delle risorse attraverso i connettori IDS. In questo contesto, il Data Retriever è integrato con la piattaforma ALIDA, dalla quale recupera le informazioni di catalogo e i metadati associati alle risorse, consentendone la pubblicazione nei Data Space tramite i connettori precedentemente registrati e configurati. Tale integrazione rappresenta una scelta implementativa coerente con l’ecosistema di riferimento, ma non costituisce un vincolo architetturale: il Data Retriever è infatti progettato per operare con sorgenti informative e cataloghi differenti, mantenendo invariato il ruolo di mediazione tra le fonti dei dati e i meccanismi di scambio.
In sintesi, il Data Retriever è un servizio che centralizza e automatizza la pubblicazione, l’aggiornamento e la gestione delle risorse informative nei Data Space. Opera come orchestratore tra sistemi sorgenti, cataloghi e connettori IDS, supportando scenari multi-dataspace. Integra meccanismi di sicurezza come OAuth2 e garantisce coerenza dei dati pubblicati, semplificando la partecipazione a ecosistemi complessi e dinamici, come quelli della filiera agroalimentare.