Data Retriever
The Data Retriever is an architectural service that automates, centralizes, and standardizes the management of information resources to be published or updated in different Data Spaces through IDS connectors.
While the Participant Template operates within the connector, the Data Retriever works upstream, acting as an orchestrator between:
- Internal systems / data sources.
- Information catalogs.
- IDS connectors to one or more Data Spaces.
This service:
- automatically retrieves datasets and metadata from internal platforms; enrichs and prepares them according to the Data Space rules; publishes them through registered connectors;
- keeps datasets updated over time;
- manages the organization's participation in multiple Data Spaces simultaneously.
The Data Retriever avoids duplication, reduces human error, and ensures that shared data is always updated. Furthermore, thanks to security standards such as OAuth2 and the use of identity management systems (such as Keycloak), it ensures that all accesses are authorized and compliant with the policies established by the data owner.
Data Retriever is therefore conceived as a service to support the operational management of traceability data throughout the various stages of the supply chain. As illustrated in the following architectural schema:
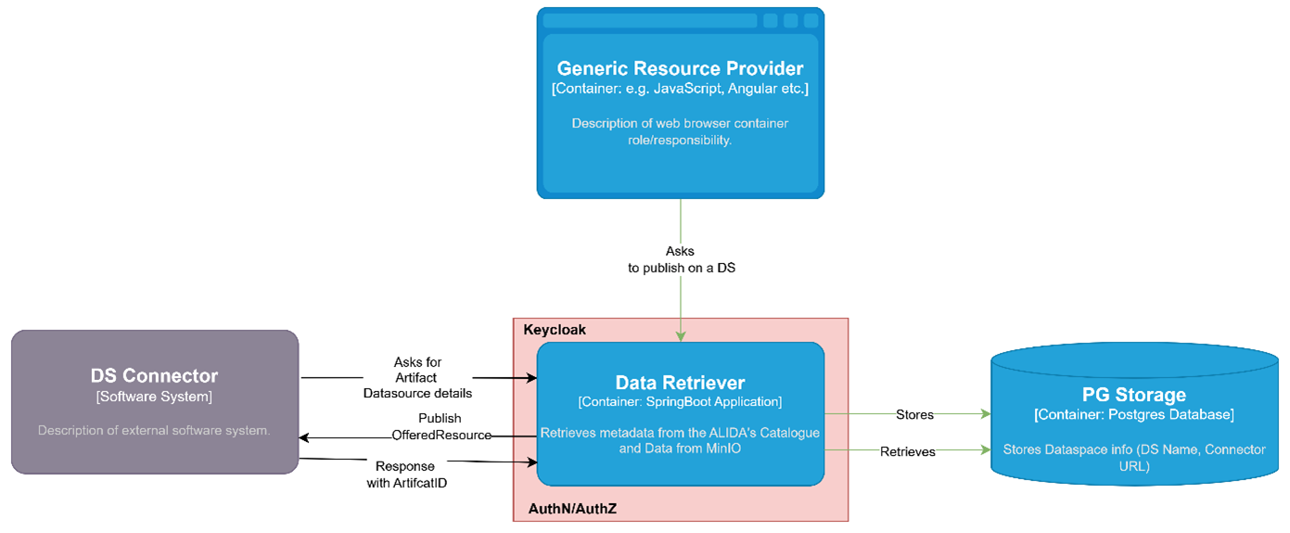
the Data Retriever acts as an intermediate component between the systems that produce or provide data, information catalogs, and Data Spaces, orchestrating publication processes and resource management through IDS connectors. In this context, the Data Retriever is integrated with the ALIDA platform, from which it retrieves catalog information and metadata associated with resources, enabling their publication in Data Spaces via previously registered and configured connectors. This integration represents an implementation choice consistent with the reference ecosystem, but does not constitute an architectural constraint: the Data Retriever is designed to operate with different information sources and catalogs, while maintaining its role as a mediator between data sources and exchange mechanisms.
In summary, Data Retriever is a service that centralizes and automates the publication, updating, and management of information resources in Data Spaces. It acts as an orchestrator between source systems, catalogs, and IDS connectors, supporting multi-dataspace scenarios. It integrates security mechanisms such as OAuth2 and ensures the consistency of published data, simplifying participation in complex and dynamic ecosystems, such as those in the agri-food supply chain.