Kubernetes Cluster
Overview
L'installazione del cluster Kubernetes e la sua gestione esulano dallo scopo di questo documento, ma si tenga presente che il Sistema Data Analytics core in sé può funzionare con una struttura di cluster minimale e con delle risorse per nodo dipendenti essenzialmente dai carichi reali.
Per quanto riguarda il cluster Kubernetes - e prendendo a riferimento alla Figura 1 - si possono fare le seguenti considerazioni.
-
Un set di nodi (Master e Worker) sono dedicati alle componenti core del Sistema Data Analytics ed ai componenti essenziali che ne costituiscono i prerequisiti.
-
Eventuali carichi extra (componenti opzionali, esecuzione di servizi dinamici) possono essere allocati su nodi supplementari (ExWrk) con un opportuno dimensionamento e con specifiche label/taint che ne consentano la precisa designazione (affinity/tolerations) in fase di schedulazione.
-
Gli host che ospitano i nodi sono interconnessi attraverso una rete LAN dedicata e non espongono porte direttamente su Internet; eventuali servizi di amministrazione sono raggiungibili via VPN.
-
È presente un host di frontend verso Internet che implementa un firewall perimetrale ed un reverse proxy che ha diverse funzioni ed in particolare
- Espone i servizi del cluster su Internet utilizzando il protocollo https mediante certificati TLS e nomi a dominio pubblici che vengono reindirizzati ai corrispondenti backend.
- Svolge il ruolo di load balancer nei confronti dei nodi del cluster.
- Implementa le Content Security Policies (CSP).
Dimensionamento
A solo scopo esemplificativo, sempre in riferimento allo schema di Figura 1, si riporta qui di seguito il dimensionamento di un'installazione dimostrativa:
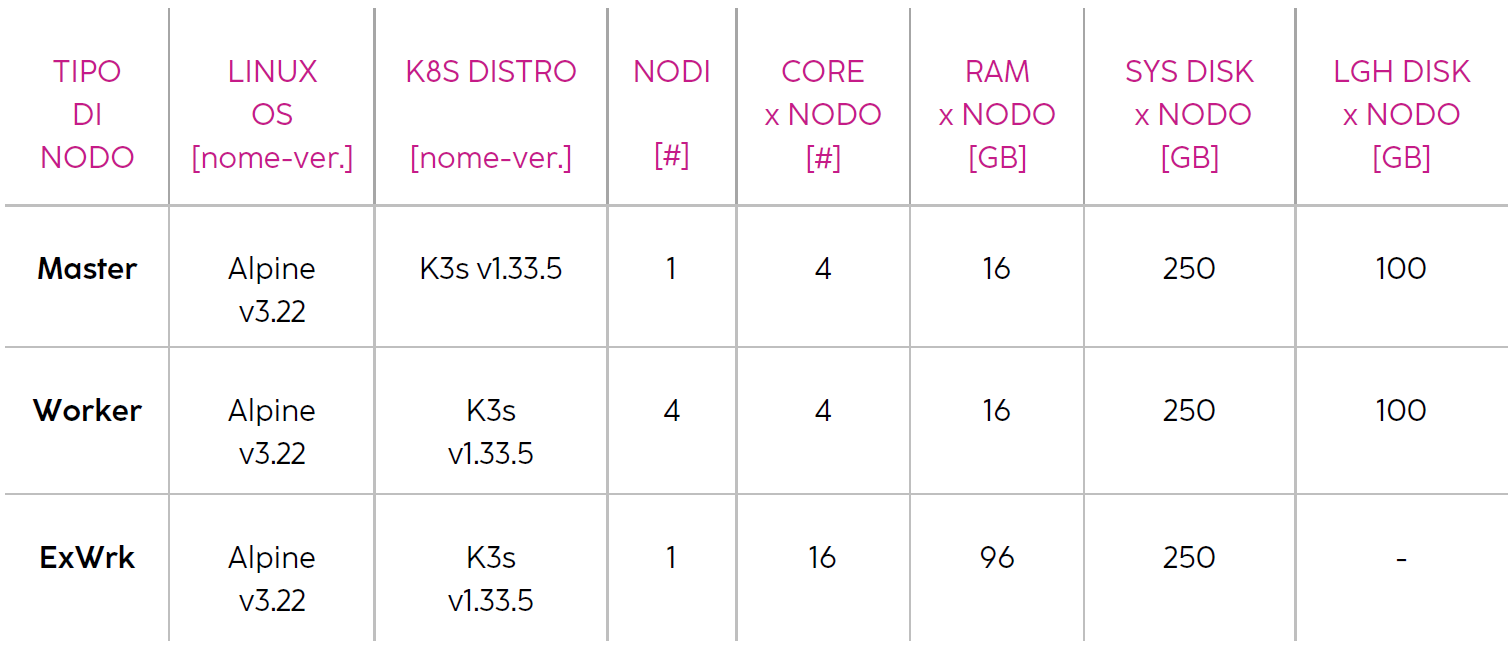
Il dimensionamento di un cluster di produzione (numero di nodi, CPU e RAM per nodo, numero e dimensionamento dei dischi di ogni nodo e/o di eventuali forme di storage centralizzati) andrà adeguato in base alla conoscenza degli specifici carichi elaborativi ed alla tipologia e taglia dei dati in gioco.
Label e Taint dei Nodi
Al fine di poter correttamente schedulare e distribuire i workload nel cluster, è necessario assegnare label ed eventualmente anche taint a gruppi di nodi.
Con riferimento alla Figura 1:
-
Ad ogni nodo master si dovrà assegnare la seguente label:
kubectl label node nodo-master --overwrite nodetype=mastered il seguente taint:
kubectl taint node k3d-alida-server-0 node-role.kubernetes.io/control-plane=true:NoScheduleNota
Questo taint non è obbligatorio e serve per evitare la schedulazione di workload applicativi sui nodi master; da usare se si hanno sufficienti nodi worker
-
Ad ogni nodo worker core si dovranno assegnare le seguenti label:
kubectl label node nodo-worker-core --overwrite kubernetes.io/role=base-workerkubectl label node nodo-worker-core --overwrite nodetype=base-worker -
Ad ogni nodo worker opzionale si dovranno assegnare le seguenti label:
kubectl label node nodo-worker-opt --overwrite kubernetes.io/role=opt-workerkubectl label node nodo-worker-opt --overwrite nodetype=opt-workered i seguenti taint:
kubectl taint node nodo-worker-opt opt-worker=true:NoSchedulekubectl taint node nodo-worker-opt opt-worker=true:NoExecute -
Qualora si preveda l'uso di workload Spark, bisognerà aggiungere un adeguato numero di nodi per tali carichi e ad ognuno di essi si dovranno assegnare le seguenti label:
kubectl label node nodo-worker-spark --overwrite kubernetes.io/role=spark-workerkubectl label node nodo-worker-spark --overwrite nodetype=spark-workered i seguenti taint:
kubectl taint node nodo-worker-spark spark-worker=true:NoSchedulekubectl taint node nodo-worker-spark spark-worker=true:NoExecute
Nomi a dominio utilizzati
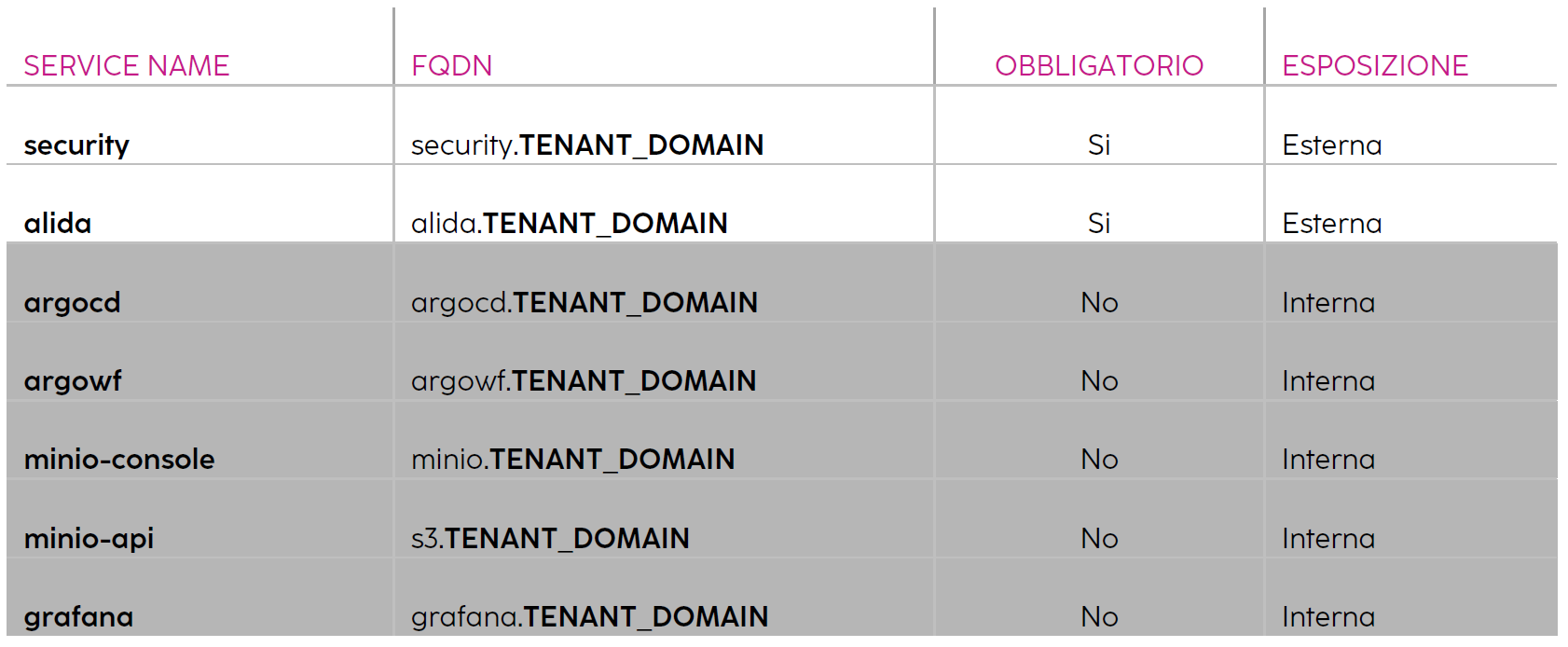
La struttura base del generico nome a dominio usata nelle linee guida è la seguente:
SERVICE_NAME.TENANT_DOMAIN
Esempio
SERVICE_NAME = alida ## varia da servizio a servizio
TENANT_DOMAIN = example.edu ## resta fisso per tutti i FQDN
-> alida.example.edu
I FQDN risultanti saranno tipicamente i seguenti: