Kubernetes Cluster
Overview
The installation and management of the Kubernetes cluster are outside the scope of this document, but it should be noted that the Data Analytics System core can function with a minimal cluster structure and resources per node dependent on the actual workloads.
Regarding the Kubernetes cluster - and with reference to Figure 1 - the following considerations can be made.
-
A set of nodes (Master and Worker) are dedicated to the core components of Data Analytics System and the essential components that constitute its prerequisites.
-
Any additional workloads (optional components, execution of dynamic services) can be allocated on supplementary nodes (ExWrk) with appropriate sizing and with specific labels/taints that allow for precise designation (affinity/tolerations) during scheduling.
-
The hosts hosting the nodes are interconnected through a dedicated LAN network and do not expose ports directly to the Internet; administration services are accessible via VPN.
-
There is a front-end host towards the Internet that implements a firewall perimeter and a reverse proxy that has several functions, in particular:
- Exposes services from the cluster on the Internet using the https protocol via TLS certificates and public domain names that are redirected to the corresponding backends.
- Acts as a load balancer for the nodes of the cluster.
- Implements Content Security Policies (CSP).
Sizing
For illustrative purposes only - and with reference to the diagram in Figure 1 - the sizing of a demonstrative installation is shown below:
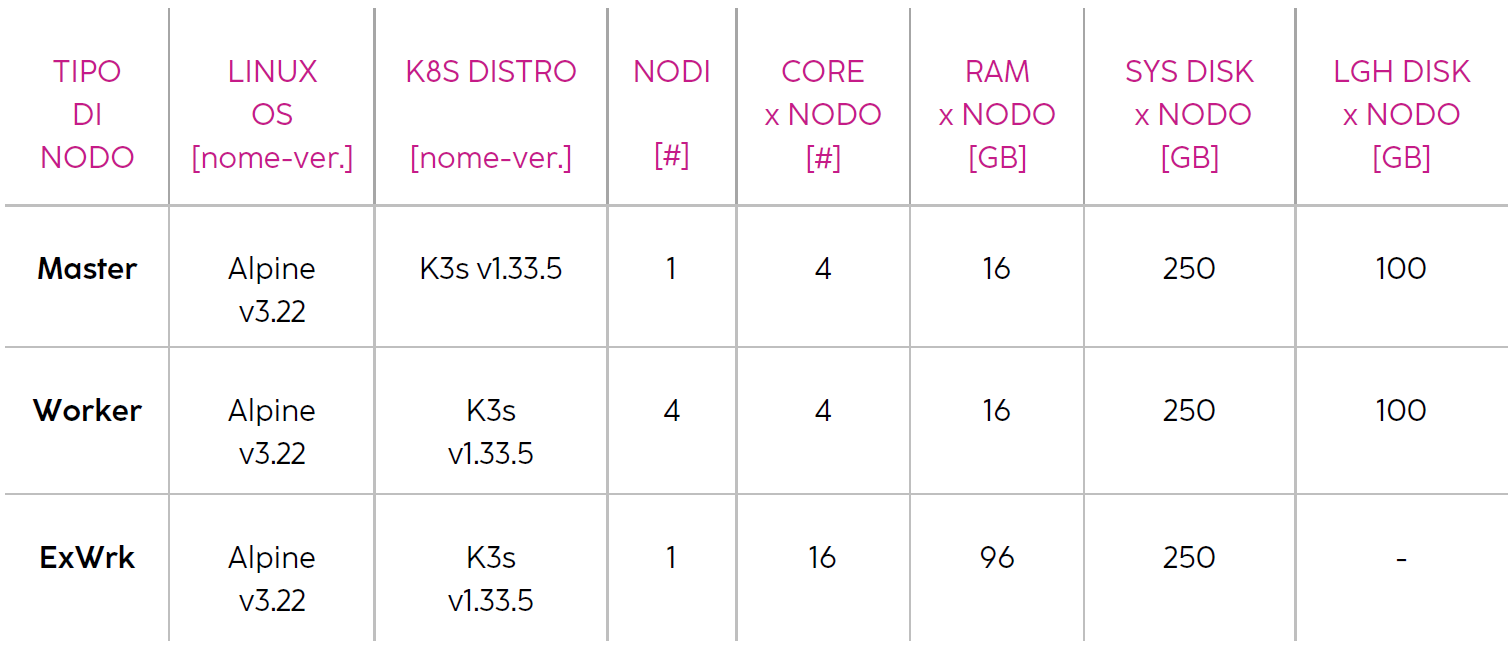
The sizing of a production cluster (number of nodes, CPU and RAM per node, number and sizing of disks for each node and/or of any centralized storage forms) must be adapted based on the knowledge of the specific processing workloads and the type and size of the data involved.
Node Labels and Taints
In order to correctly schedule and distribute workloads within the cluster, it is necessary to assign labels and, optionally, taints to groups of nodes.
With reference to Figure 1:
-
To each master node, the following label must be assigned:
kubectl label node nodo-master --overwrite nodetype=masterand the following taint:
kubectl taint node k3d-alida-server-0 node-role.kubernetes.io/control-plane=true:NoScheduleNote
This taint is not mandatory and serves to prevent the scheduling of application workloads on the master nodes; to be used if there are sufficient worker nodes
-
To each core worker node, the following labels must be assigned:
kubectl label node nodo-worker-core --overwrite kubernetes.io/role=base-workerkubectl label node nodo-worker-core --overwrite nodetype=base-worker -
To each optional worker node, the following labels must be assigned:
kubectl label node nodo-worker-opt --overwrite kubernetes.io/role=opt-workerkubectl label node nodo-worker-opt --overwrite nodetype=opt-workerand the following taints:
kubectl taint node nodo-worker-opt opt-worker=true:NoSchedulekubectl taint node nodo-worker-opt opt-worker=true:NoExecute -
Should the use of Spark workloads be foreseen, an adequate number of nodes for such workloads must be added and to each of them the following labels must be assigned:
kubectl label node nodo-worker-spark --overwrite kubernetes.io/role=spark-workerkubectl label node nodo-worker-spark --overwrite nodetype=spark-workerand the following taints:
kubectl taint node nodo-worker-spark spark-worker=true:NoSchedulekubectl taint node nodo-worker-spark spark-worker=true:NoExecute
Domain Names Used
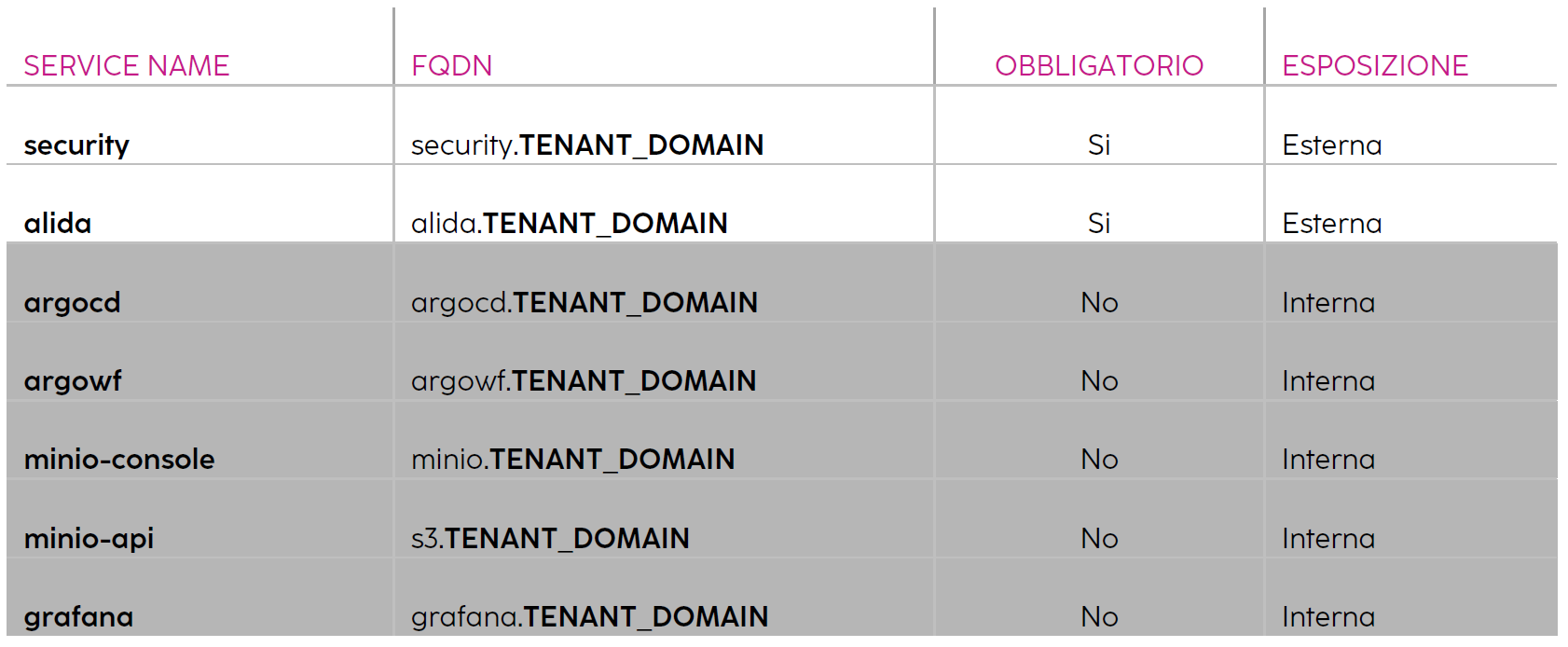
The basic structure of the generic domain name used in the guidelines is as follows:
SERVICE_NAME.TENANT_DOMAIN
Example
SERVICE_NAME = alida ## varies from service to service
TENANT_DOMAIN = example.edu ## remains fixed for all FQDN
-> alida.example.edu
The resulting FQDNs will typically be the following: